Billboard Hot 100 Lyric Analysis
Introduction
The Billboard Hot 100, from billboard.com, is a list of rankings for the most popular 100 songs of a given week. The website claims to establish their rankings by "...fan interactions with music, including album sales and downloads, track downloads, radio airplay and touring as well as streaming and social interactions on Facebook, Twitter, Vevo, Youtube, Spotify and other popular online destinations for music." (billboard.com, 2017).
In this analysis the goal is to see if any trends appear within the song's lyrics through text analysis. This project was created purely out of personal interest to see if any lyrical patterns exist between popular songs. All of the code and data used during this analysis can be viewed at the following GitHub repository.
Please take caution while reading this blog post. Some offensive language is used for analysis purposes.
Methods
In this section we explore the methods and tools used to extract data from sources, clean the data and analyze the text.
Data Collection
The first task at hand was to determine which data sources provided the song list and the lyrics. Thankfully, billboard.com provided an RSS feed that could easily be parsed to process the top 100 songs for a given week while obtaining the lyrics was much more difficult. To parse the RSS feed, I used the Python programming language and the software libraries: LXML and Requests. LXML provides functionality to process DOM elements on web pages (HTML and XML). The Requests library enables you to create HTTP requests to obtain web content.
The billboard.com RSS feed was obtained by making a GET request with the Request's library and further parsed using LXML. For every song in the RSS feed, the artist, title, rank this week, rank last week was collected. During the iteration of each RSS entry, a request to a lyric site was made to obtain the lyrics (discussed below). Once processed, a comma-delimited file was created to save the song entries. A simple illustration of this process is shown below.

Searching for websites that provided lyrics was the longest process in this whole project. There are several lyrics websites available, however many of them are community driven and do not always have every song's lyrics at hand. That created a challenge in creating a good combination of many different web sources to obtain lyrics from. AZLyrics.com, SongLyrics.com and LyricsFreak.com were all used to obtain lyrics. The process consisted of using the Requests and LXML libraries in the Python programming language. Essentially, the script would create a search request on each site until it found lyrics it was looking for. Once the lyrics were found it would extract them from the web page and save them to a text file. If one website did not have the lyrics, it would try the next one. If none of the sites contained the lyrics, it would raise an error. In the case of an error, manual web searching is required to obtain the lyrics. To create the file name for the lyrics file, I used the Python library unicode-sluggify.This library "sluggifies" the provided text replacing spaces with dashes and other symbols accordingly. It is normally used in creating "pretty" URLs.
In addition to the top songs and lyrics, I collected a set of swear words from noswearing.com. NoSwearing.com provides a list of swear words that are both common and uncommon. To extract these swear words I used the same libraries (Requests and LXML) to scrape data from the website. The website is laid out with all swear words separated alphabetically on their own web page. The script used to scrape the words iterated through the alphabet constructing the URL accordingly and fetched the swear words saving them to a text file.
Data Cleansing
Preparation of the lyrics files consisted of removing unwanted text within the files. Many of the files contained labels in brackets to mark the chorus and other constructs of a song. These were removed from the files. Additionally, some lyrics files had a line that consisted of "Produced by..." which was removed. All data cleansing techniques used regular expressions in the Python programming language. Prior to this data cleansing step, raw data analysis was performed to determine what was causing "dirty results".
Text Processing and Visualization
The Python language and the following libraries were used to process and visualize the text: NLTK, Pandas and Matplotlib. NLTK is a natural language processing tool kit that provides convenience functions for common tasks such as tokenization and sentiment analysis. The Pandas library is a tool that provides common data analysis features. It enables you to easily perform aggregations, obtain descriptive statistics and plot data by wrapping convenience methods from other libraries. When Pandas didn't provide the exact plotting styles that I wanted out of the box, I used Matplotlib functionality to add styling to the plots.
Analysis
In this section you will find the different analyses performed on the lyrics.
Word Frequency
One of the first analyses performed was to determine the frequency of words throughout the lyrics. This process was performed by tokenizing each of the words with NLTK, removing the stop words, stemming words with PorterStemmer, collecting word frequencies per lyrics file and normalizing the word frequency. Normalization was performed by treating each set of lyrics individually and collecting the frequency that each word showed up in the lyrics file individually. Once a frequency was obtained for each set of lyrics, a global frequency was calculated by combining all local frequencies and dividng by 100 (the number of songs). This method essentially treats every lyrics file as a "bag of words instead of all lyrics text combined as a "bag of words".
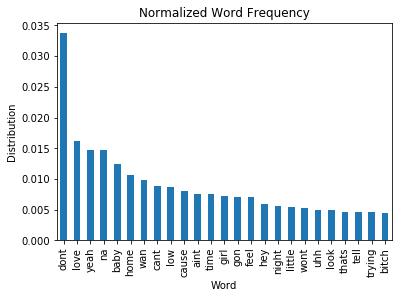
The bar chart above shows some of the common words used throughout the songs. The Y-axis is the frequency in a decimal percentage while the X-axis displays the words. So the word "love" shows up 1.5% of the time in all of the songs. Looking at the word frequencies could give you a general idea that "love" is a fairly popular topic in this set of songs.
Swear Words
The next analysis performed was to look at how frequent swear words occurred in the songs. The same process used to obtain the word frequency was used to calculate the swear word frequency with one additional step - filtering the words of interest.
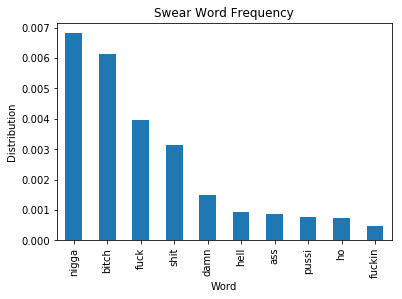
As illustrated in the plot, there is a very low frequency of swear words found throughout these songs. The most frequent swear word has a frequency of 0.7%. I imagine this is due to the nature of how billboard.com collects their information to create their list or songs with many swear words just are not as popular. Speculation aside, this would require more analysis and data collection on this specific topic to reliably determine the case.
N-Grams
Similar to looking at common words in the songs, I looked for common N-Grams. An N-Gram is a contiguous set of text. In this case our N-Grams represent a number of words.
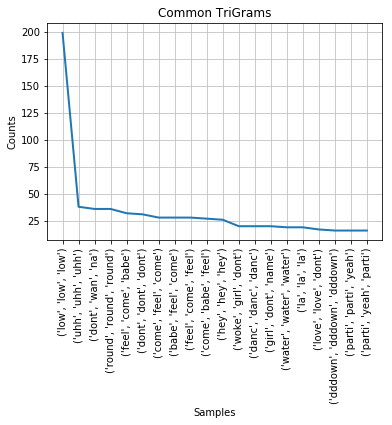
The plot above shows the top TriGrams with their frequency.
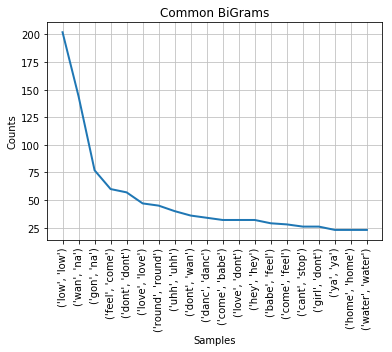
The plot above shows the top BiGrams with their frequency. You might notice that there isn't a big difference between looking at TriGrams versus BiGrams. The majority of the same results show as the top.
Sentiments
To gain insight into the general sentiment of these popular songs, the Vader sentiment analysis algorithm was used. This algorithm is a rule-based algorithm that was trained with Twitter data. It provides a good solution to handling slang and emoticons that isn't always seen in most algorithms. Another approach, given that I collectd more data, would be to create my own sentiment analysis tool using a NaiveBayes model. However, for this particular problem I felt that Vader would suffice. This is primarily due to no known source of lyrics with labeled sentiments.
I used the Vader algorithm on each individual line in a given lyrics file. The output of the algorithm is a probability score of neutrality, positivity and negativity. To obtain the sentiment for an entire song, each line was processed and the sum of each probability was gathered. Once all lines were processed, a normalized score was obtained by dividing by the total number of lines analyzed in the lyrics file. To obtain a global sentiment for all of the songs in the set, each song's sentimet scores were summed and divided by the total number of songs analyzed (100).
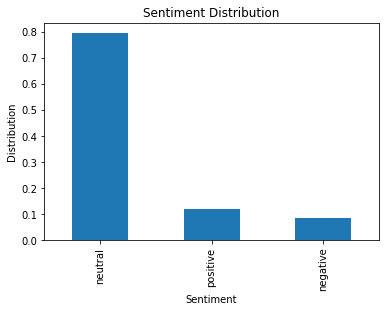
In this plot you can see that the songs are generally scored as neutral, however there is a 2-3% difference between positive and negative sentiments. I imagine that the sentiment analysis tool, Vader, is most likely not optimal for lyric analysis. Experimentation with other algorithms would need to be explored to determine if a better solution is available.
Repetitiveness
Have you ever listened to a song that seemed as if it was saying the same thing over and over again? Typically these songs become "stuck in your head" so I wanted to measure how repetitive a given song is. A custom algorithm was used to measure repetitiveness. Essentially, all unique phrases (each individual line) was obtained for each lyric file and a frequency for each phrase was calculated. All unique phrases that had 2 or more repetitions was summed together and divided by the total number of phrases in the file. The result is a percentage of repetitive lines.
A different approach for measuring repetitiveness would be at the word level. However, some songs use words in different phrases that may not sound repetitive. Either approach would work, however I felt that measuring at the phrase level made more sense.
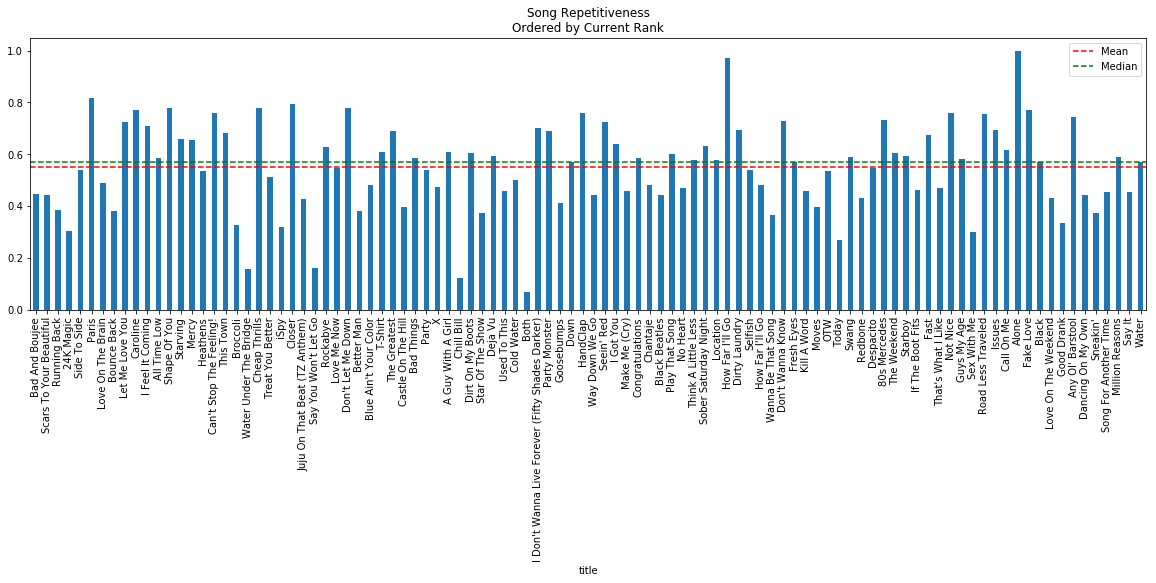
The plot above shows the percentage of repetitions found in each song. The songs from left to right are ordered by the 1st rank for the week to the 100th rank. You can also see that generally a lot of these songs are pretty repetitive with a median of nearly 58%. Althougth these songs may seem very repetitive, more data would need to be analyzed to get a better median and mean repetition percentage. In other words, it is difficult to say that these songs are very repetitive when we do not know how repetitive most songs are.
Correlations
I looked for trends between sentiments, current rank and repetitiveness. However, no strong correlations were found. The Pearson correlation was used to identify any potential correlations. Pandas provides a simple way to obtain all correlations in a table format between all numerical values. For illustration, I included some scatter plots.
![]()
![]()
![]()
Conclusion
While no correlations were found within the lyrics, many useful techniques and insights were gained in our analysis. We found that within our samples swearing is fairly limited with less than a 1% frequency, songs contain generally neutral sentiment with similar measures of positivity and negativity and that there appears to be a fairly high number of repititions in songs.
Some things to take note of is that all of these songs come from different genres and artists which makes finding trends more difficult. Also, it may not only be lyrics that make a song popular.
Here is a list of further analysis topics that could be interesting:
- Temporal analysis of Billboard Hot 100 songs across a year's period.
- All songs for a particular artist.
- Many songs from a particular genre.
- Many songs from multiple genres treated as separate cohorts.
- Improve sentiment analysis by training our own model. This would be very complicated with no labels.
- Combine a songs audio and lyrics to perform a similar analysis.